最近跑模型的时候发现GPU利用率奇低,基本维持在百分之十几左右,还会间歇性掉到0,导致训练60K个iteration就需要接近3天的时间,而官方论文的训练总数是整整600K iteration,这就意味着如果我要跑一次全量训练起码要30天,这肯定是无法接受的,因此需要定位问题再进行性能优化。
PyTorch Profiler是PyTorch 1.8+内置的全栈性能分析器 ,可一键记录CPU、GPU、内存、数据传输、算子调用栈 等细粒度指标,并直接输出TensorBoard 可视化 或Chrome Trace 文件,帮助快速定位训练/推理瓶颈。
根据官方文档,将训练代码放到以下代码之内:
1 2 3 4 5 6 7 8 9 10 11 12 13 with profile( activities=[torch.profiler.ProfilerActivity.CPU, torch.profiler.ProfilerActivity.CUDA], schedule=torch.profiler.schedule(wait=1 , warmup=1 , active=4 , repeat=1 ), on_trace_ready=tensorboard_trace_handler("./train_log" ), with_stack=True , profile_memory=True , record_shapes=False , ) as prof: prof.step() if iteration >= 1 + 1 + 4 : return
运行之后就能在同级目录里看到trace.json文件,然后安装tensorboard的profiler插件:
1 pip install torch_tb_profiler
使用tensorboard打开trace文件:
1 tensorboard --logdir=./train_log
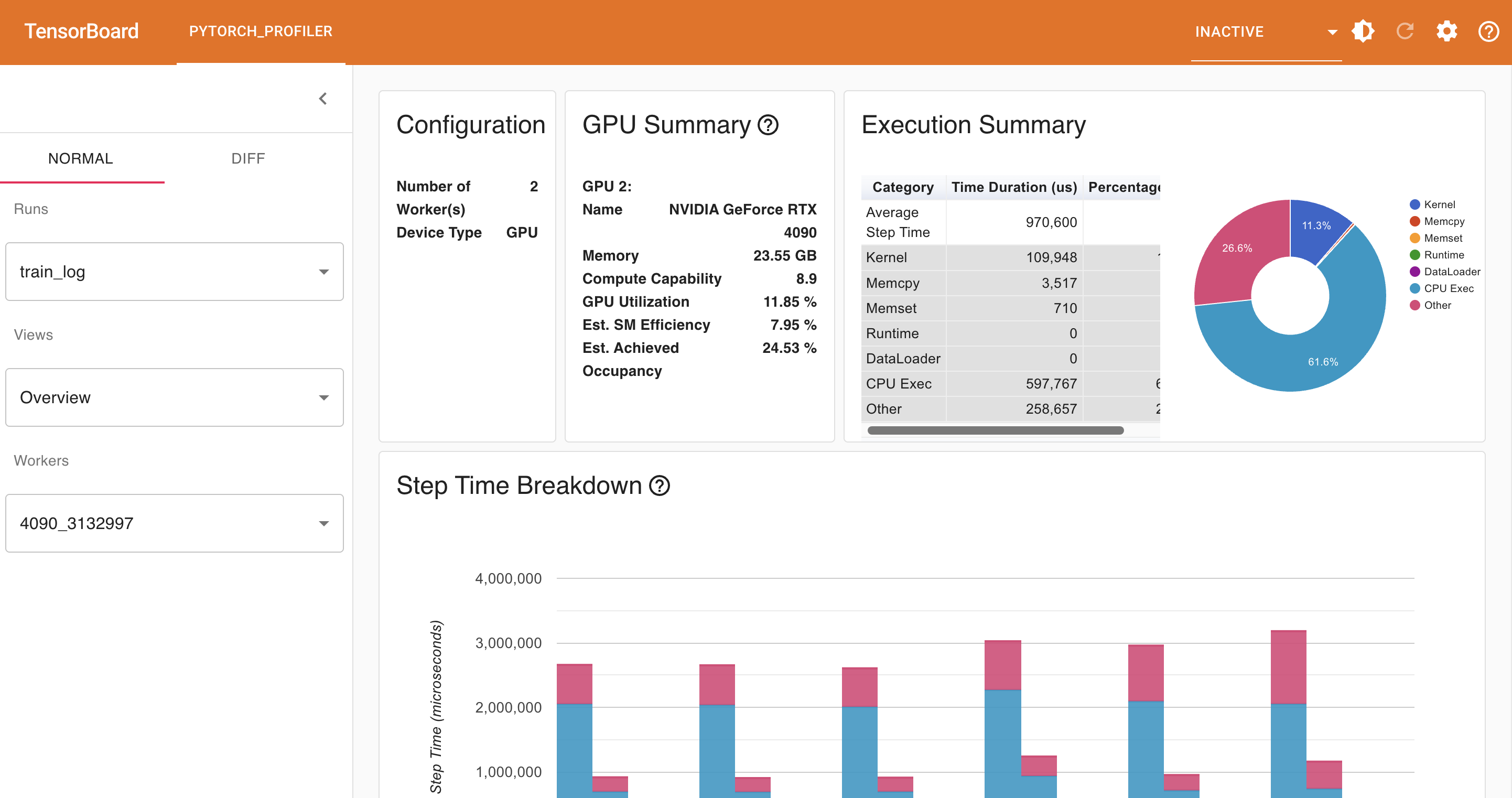
在面板中可以看到各种操作的时间占比,但是不知道为什么我这里看不到Dataloader的时间占比,即便我按照某issue里面说的把Dataloader的num_workers设置为0,使数据加载发生在主线程里,依然没法解决这个问题。无论如何,从面板可以看出GPU利用率只有11.85%,Kernel操作只占了运行时间的11.3%,性能亟待优化。
然后我在profiler_tutorial 的warning里看到tensorboard和profiler的集成已经弃用了,可以使用Perfetto UI 来分析trace文件,用其打开trace文件终于能够显示Dataloader的数据了,根据分析结果可以看到在一个iteration中Dataloader的运行时间达到了4s左右,模型的forward方法在900ms左右,backward则在1.4s左右,很明显性能瓶颈在于数据加载,需要针对Dataset类进行优化。
LMDB是一个高性能、嵌入式键值数据库 ,被广泛用于需要低延迟、高并发读 的场景,LMDB整库就是单个文件,通过 mmap() 一次性映射到进程地址空间,可以减少文件寻址的时间。网上大多博客在谈数据加载优化时首要提到的就是将数据集转换为lmdb格式,故采用如下代码进行转换,在转换时,我把图片转换为了tensor bytes再进行存储,读取时就可以使用torch.load直接转换为tensor,而不需要再进行图片解码,但是要注意存储的tensor是uint8类型的,如果存储float32则会导致占用空间大大增多,增加的io耗时会多于减少的解码耗时,得不偿失:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 for i, (key, img_path) in enumerate (tqdm(img_meta, desc="转换并写入 LMDB" )): try : img = Image.open (img_path).convert('RGB' ) np_img = np.array(img) tensor = torch.from_numpy(np_img) tensor = tensor.permute(2 , 0 , 1 ).contiguous() tensor_bytes = tensor.numpy().tobytes() txn.put(key.encode('utf-8' ), tensor_bytes) except Exception as e: print (f"\n处理文件 {img_path} 时出错: {e} " ) continue if (i + 1 ) % write_frequency == 0 : txn.commit() txn = env.begin(write=True ) txn.commit() env.close()
经过测试,LMDB确实加快了数据读取,但是dataloader依旧是瓶颈,还需要进一步优化。torch profiler的trace可以直观地看出瓶颈在哪,但是要具体到各行代码的耗时分析时就不够好用了,因此下面转用line_profile来进行分析。line_profiler可以给出各行代码的时间占比、执行次数等信息,直接用pip安装即可,然后在Dataset类的__get_item__方法上添加@profile装饰器,使用kernprof -l -v test.py命令来启动一个迭代读取Dataset的代码,最终会在终端里打印各行代码耗时信息,把代码里耗时比较高的挑出来,结果如下:
1 2 3 4 5 6 7 8 9 Line # Hits Time Per Hit % Time Line Contents ============================================================== 135 3030 11093407.8 3661.2 9.3 hr_img_bytes = self._get_data_from_lmdb(self.img_env, hr_img_key) 139 3030 24507465.6 8088.3 20.5 lr_img = torch.load(io.BytesIO(lr_img_bytes)).float() / 255.0 140 3030 32407331.8 10695.5 27.1 hr_img = torch.load(io.BytesIO(hr_img_bytes)).float() / 255.0 156 3030 12741764.0 4205.2 10.7 hr_depth_bytes = self._get_data_from_lmdb(self.depth_env, hr_depth_key)
行号135的代码用于从LMDB数据库中读取高分辨率图片的bytes数据,行号156则是读取高分辨率图对应的深度图,行号139-140则是将bytes数据转换为低分辨率图片和高分辨率图片,然后转换数据类型并进行归一化。这四行代码的耗时占比基本都在10%以上,存在可优化空间。
同时使用代码从Dataset中读取100个batch,整体耗时达到了119.64s,平均1.2s读取一个batch。
针对lr_img = torch.load(io.BytesIO(lr_img_bytes)).float() / 255.0这行代码,我原以为其瓶颈在于torch.load操作,但是当我把这行代码分为torch.load、lr_img = lr_img.float()和lr_img = lr_img / 255.0时才发现最后这个除法操作的耗时远远大于前两步。
经过调研发现,lr_img = lr_img / 255.0是需要先开辟一块新内存用于存储结果,然后再进行除法操作的,而pytorch中提供了div_()方法来进行原地除法,无需开辟新内存,使用以下代码来比较两者的性能差异:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import torch, timex = torch.randn(3 , 720 , 1280 , dtype=torch.float32) torch.cuda.synchronize() t0 = time.time() for _ in range (100 ): y = x / 255.0 torch.cuda.synchronize() print ("out-of-place:" , time.time() - t0, "s" )torch.cuda.synchronize() t0 = time.time() for _ in range (100 ): x.div_(255.0 ) torch.cuda.synchronize() print ("in-place:" , time.time() - t0, "s" )
最终结果如下,两者性能差距将近21倍:
1 2 out-of-place: 0.12485671043395996 s in-place: 0.005963802337646484 s
再次使用line_profiler进行分析,除法操作的时间占比大幅降低:
1 2 3 4 5 6 7 8 9 Line # Hits Time Per Hit % Time Line Contents ============================================================== 134 3030 1165666.1 384.7 2.5 lr_img = torch.load(io.BytesIO(lr_img_bytes)) 135 3030 2003618.1 661.3 4.3 hr_img = torch.load(io.BytesIO(hr_img_bytes)) 138 3030 1288034.8 425.1 2.7 lr_img = lr_img.float() 139 3030 290921.0 96.0 0.6 lr_img.div_(255.0) 140 3030 1087394.6 358.9 2.3 hr_img = hr_img.float() 141 3030 195675.0 64.6 0.4 hr_img.div_(255.0)
再次测试读取100个batch的时间,总共耗时46.88s,提速相当明显。
在原来的__get_item__函数中,对于低分辨率图片和高分辨率图片是交替读取的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 for i, img_path_dict in enumerate (img_seq): lr_img_path = img_path_dict["lr_img_path" ] hr_img_path = img_path_dict["hr_img_path" ] lr_img_key = os.path.relpath(lr_img_path, self.img_root) hr_img_key = os.path.relpath(hr_img_path, self.img_root) lr_img_bytes = self._get_data_from_lmdb(self.img_env, lr_img_key) hr_img_bytes = self._get_data_from_lmdb(self.img_env, hr_img_key) lr_img = torch.load(io.BytesIO(lr_img_bytes)).float () hr_img = torch.load(io.BytesIO(hr_img_bytes)).float () lr_img.div_(255.0 ) hr_img.div_(255.0 )
而前面提到,LMDB是使用B+树来组织数据的,我们都知道,B+树的相邻叶子节点之间存在指针,从而优化了顺序访问的速度,而高分辨率图片和低分辨率图片的key是不一样的,高分辨率的key之间是顺序的,低分辨率的key之间也是顺序的,而上面这种读取一张低分辨率图片又去读取一张高分辨率图片的做法就无法享受到B+树的优化了。
因此我把低分辨率图片和高分辨率图片的读取聚在了一起:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 with self.img_env.begin(write=False ) as txn: for i, img_path in enumerate (img_seq): lr_img_path = img_path["lr_img_path" ] lr_img_key = os.path.relpath(lr_img_path, self.img_root) lr_img_bytes = txn.get(lr_img_key.encode('utf-8' )) lr_img = torch.load(io.BytesIO(lr_img_bytes)).float () lr_img.div_(255.0 ) lrs.append(lr_img) for i, img_path in enumerate (img_seq): hr_img_path = img_path["hr_img_path" ] hr_img_key = os.path.relpath(hr_img_path, self.img_root) hr_img_bytes = txn.get(hr_img_key.encode('utf-8' )) hr_img = torch.load(io.BytesIO(hr_img_bytes)).float () hr_img.div_(255.0 ) hrs.append(hr_img)
再次测试100个batch读取时间,用时22.056s。
除了以上的优化以外,我发现在训练过程中模型并不需要用到高分辨率图的深度图,因此删掉了读取代码,也带了很大的速度提升,不过没什么技术性,在此不赘述。
使用优化后的数据集再跑一次pytorch profiler分析,最终结果如下图所示:
可以看到相比模型推理和反向传播,数据集加载要短得多。然而跑训练时虽然能够感受到一点提速,但是GPU利用率也仅仅是稳定在50%左右,还不是很理想,目前仍在想办法优化其他部分的代码。