因为《数字媒体导论》课程要做文献汇报,同组同学选择了和扩散模型相关的论文,而我又没接触过扩散模型,正好学习并整理一下DDPM模型的推导过程。
1. DDPM
扩散模型(Diffusion Model)是一种基于概率生成模型的深度学习方法,核心通过前向扩散(逐步加噪)和反向扩散(逐步去噪)两个对称的马尔可夫链,实现从随机噪声到真实数据的生成。

DDPM是扩散模型中的代表性工作,来自2020年发表的《Denoising Diffusion Probabilistic Models》:
1.1 前向扩散
前向扩散的目的是从真实数据 x0出发,按固定规则逐步添加高斯噪声,最终得到纯噪声 xt(t为总步数)。前向扩散的核心是缓慢加噪,确保每一步噪声强度可控,且最终 xt 近似标准高斯分布 N(0,I),加噪过程如下:
q(xt∣xt−1)∼N(1−βt⋅xt−1,βtI)
即对于xt−1中的每个像素,以其像素值乘以1−βt为均值,βt为方差,按照正态分布来随机采样一个值作为下一步图像的像素值。其中I是单位矩阵;βt∈(0,1)为预定义的噪声强度,通常设定为从 0.0001 到 0.02 的递增序列(前期加少量噪声,后期加大量噪声,避免数据过早失真),从x0开始重复以上操作t次则可以得到噪声图片。
但是这样的循环操作会非常耗时,为了简化计算,可以采用重参数化技巧来将t次操作转变为一次操作,将(1)式利用标准正态分布来展开:
xt=1−βt⋅xt−1+βt⋅ϵt−1ϵ∼N(0,1)
即当前图像等于上一步图像和一个高斯噪声项的加权和,定义α=1−β,再将xt−1递推展开:
xt=αt⋅xt−1+1−αt⋅ϵt−1=αt⋅(αt−1⋅xt−2+1−αt−1⋅ϵt−2)+1−αt⋅ϵt−1=αtαt−1⋅xt−2+αt(1−αt−1)ϵt−2+1−αtϵt−1
我们知道,将两个正态分布相加,最后仍然是正态分布,所得正态分布的方差为两者之和,那么对于上式最后的两个高斯噪声项,将它们相加可以用一个单个高斯噪声来代替:
αt(1−αt−1)ϵt−2∼N(0,αt−αtαt−1)1−αtϵt−1∼N(0,1−αt)αt(1−αt−1)ϵt−2+1−αtϵt−1∼N(0,1−αtαt−1)xt=αtαt−1xt−2+1−αtαt−1ϵ
我们不断地进行递推展开至x0,最后就可以得到如下式子:
xt=αtˉx0+1−αtˉϵt
其中αtˉ=Πi=1tαi,由此我们无需从 x0 逐步计算到 xt,可直接计算任意 t 步的加噪数据,为后续训练提供便捷。
1.2 反向扩散
反向扩散是扩散模型的核心学习部分,目标是从 xt 出发,逐步推断 xt−1,…,x0,即计算p(xt−1∣xt),但是这个分布我们无法直接计算,因此DDPM利用马尔可夫链的性质来对其进行转化。马尔可夫链中,时间步t的随机变量仅依赖于前一个随机变量,而与更前面的随机变量无关,故有p(xt−1∣xt)=p(xt−1∣xt,x0),后者意思是在xt和x0同时发生的情况下xt−1发生的概率。
对于p(xt−1∣xt,x0)可以利用贝叶斯公式进一步展开。根据贝叶斯公式P(A∣B,C)=P(B∣C)P(B∣A,C)P(A∣C),将p(xt−1∣xt,x0) 代入这个公式则可以得到:
p(xt−1∣xt,x0)=p(xt∣x0)p(xt∣xt−1,x0)p(xt−1∣x0)
公式右边由三个概率分布组成,对于p(xt∣xt−1,x0),再次利用马尔可夫链的性质,将其转换为p(xt∣xt−1),则有
p(xt−1∣xt,x0)=p(xt∣x0)p(xt∣xt−1)p(xt−1∣x0)
如此,右式的三个概率分布都是我们已知的正态分布,p(xt∣xt−1)是前向过程中的一步,而另外两项则可以用之前提到的重参数化的公式xt=αtˉx0+1−αtˉϵt 来给出它们的分布:
p(xt∣xt−1)=N(αtxt−1,βtI)p(xt−1∣x0)=N(αˉt−1x0,(1−αˉt−1)I)p(xt∣x0)=N(αtˉx0,(1−αtˉ)I)
接下来运用正态分布的乘法和除法公式即可给出p(xt−1∣xt,x0)的分布,正态分布乘法和除法公式如下:
N(μa,σa2)⋅N(μb,σb2)∝N(μc,σc2)σc21=σa21+σb21σc2μc=σa2μa+σb2μb
N(μb,σb2)N(μa,σa2)∝N(μc,σc2)σc21=σa21−σb21σc2μc=σa2μa−σb2μb
将三个正态分布代入以上公式,最后可以得到:
p(xt−1∣xt,x0)=N(1−αˉtαˉt−1βtx0+1−αˉtαt(1−αˉt−1)xt,1−αˉt(1−αˉt−1)βt)
σ2中的系数是由我们在前向过程中定义的,因此σ2可以直接计算,而在μ中出现了项x0,但是在反向过程中,x0是不给出的,因此利用前面的重参数化公式xt=αtˉx0+1−αtˉϵt反解出x0:
x0=αˉtxt−1−αˉtϵt
代入μ中可得:
μ=αt1(xt−1−αˉt1−αtϵt)
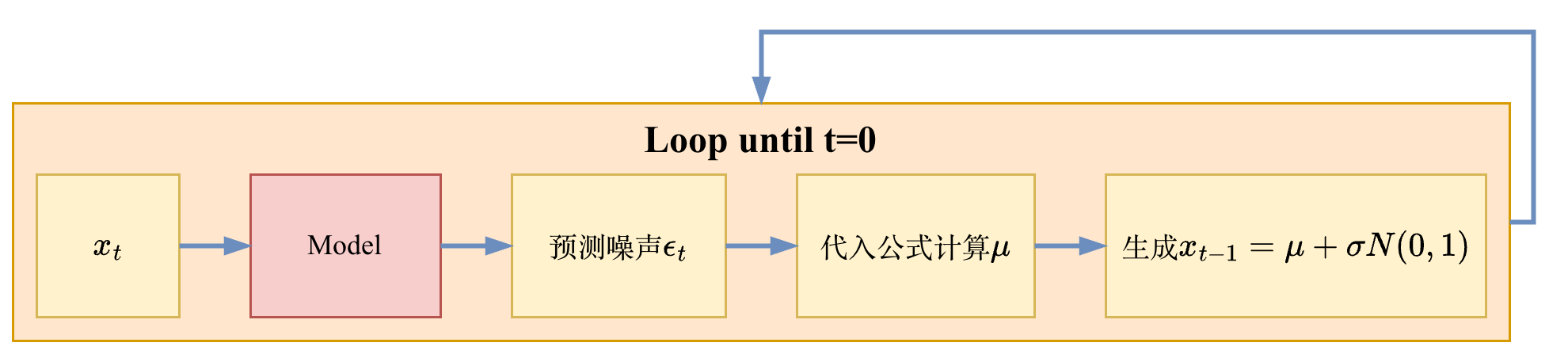
如此,整个μ中只剩下一个未知项ϵt,因为这个噪声是在前向过程中生成的,反向过程中不能获取这个噪声的值,因此我们可以让模型来预测这个ϵt的值,再根据公式来得到xt−1的分布,如此循环直到我们计算出x0,其流程如下所示: